近日,斯坦福大學的Hazy Research團隊公布了一項突破性的優化成果,他們成功地將開源模型Llama-3.2-1B的前向推理過程整合為一個名為“Megakernel”的巨型內核,這一創新將低延遲推理能力推向了新的極限。
在對話式AI和人類參與的交互式工作流等實時性要求極高的應用中,大語言模型的響應速度至關重要,直接關系到用戶體驗的好壞。然而,現有的開源推理引擎在處理這類極低延遲的單序列生成任務時,即使在頂級GPU如H100上,也往往無法充分利用其內存帶寬。
Hazy團隊經過深入研究后發現,限制LLM推理速度的關鍵瓶頸在于內存加載問題。具體來說,現有的推理引擎將Transformer模型的每一層拆解成數十甚至上百個CUDA kernel,每個kernel只執行非常小的操作,如RMS norm、注意力計算、MLP、Rotary Position Embedding等。這種拆解方式導致大量的上下文切換和等待時間,使得GPU在大部分時間里都處于“等待干活”的狀態,而非“在干活”。
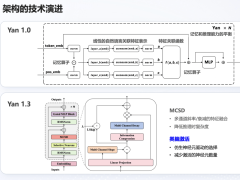
為了解決這個問題,Hazy團隊提出了一個激進但有效的設計思路:將整個前向傳播過程整合為一個單一的CUDA kernel,即Megakernel。他們基于已有的ThunderMLA架構,開發了一個輕量的GPU指令解釋器系統,該系統為每個Streaming Multiprocessor(SM)預先分配一段包含多條按順序排列指令的“執行計劃”,每條指令代表Transformer模型中的一個結構單元。
這些指令包括融合RMSNorm、QKV projection、RoPE的復合指令,attention矩陣乘與縮減計算,O-projection與residual相加,MLP的RMSNorm、gate激活(SiLU)與上投影,down projection和最終residual,以及最后一層的RMSNorm加語言建模頭。這些指令都基于統一的CUDA模板構建,實現了對load、store、compute的標準化封裝。
為了確保高效的數據路徑,解釋器會將這些執行計劃按模型結構靜態編排,避免調度時的動態分支,從而提升吞吐與并發執行能力。同時,為了實現流水化計算并防止shared memory沖突,團隊還對GPU的共享內存進行了分頁管理,確保下一個計算階段可以盡早開始預加載權重,從而最大化帶寬使用率并消除“氣泡”。
實驗結果顯示,Megakernel在H100上的推理延遲壓縮至不足1毫秒,顯存帶寬利用率高達78%,相較于vLLM提升了2.5倍,相較于SGLang提升了1.5倍。在更先進的B200平臺上,延遲進一步降低至600~680微秒,逼近理論極限。從一次完整推理的時間分布來看,Megakernel在存儲激活、等待一致性與數據加載、RMSNorm與matvec等方面都表現出了卓越的性能。
Hazy團隊的研究還揭示了一個關鍵問題:為什么現在主流的LLM推理系統在小batch、極低延遲場景下表現如此“不給力”。他們發現,像vLLM和SGLang這樣的系統,在處理生成一個token這種極限情況時,GPU的顯存帶寬利用率非常低。核心原因是模型前向過程被拆成了太多太小的CUDA kernel,導致GPU在頻繁切換kernel時產生了大量的固定成本和時間浪費。
因此,Hazy團隊提出的核心解決方案是消除這些kernel邊界,讓GPU不再頻繁切換任務。他們通過整合前向傳播過程為單個Megakernel,實現了系統性優化。這一創新不僅提高了推理速度,還充分利用了GPU的顯存帶寬,為實時性要求極高的應用提供了強有力的支持。
Hazy團隊還對CUDA異步屏障的性能進行了測量,并發現不同硬件架構上Megakernel的最佳實現路徑應有所不同。例如,在Hopper架構(如H100)上,使用常規CUDA核心可能更有效;而在Blackwell架構上,Tensor Core則性能更優。這一發現為Megakernel在不同平臺上的優化提供了重要指導。
總的來說,Hazy Research團隊的Megakernel創新為LLM推理性能的優化提供了新的思路和方法。通過整合前向傳播過程為單個巨型內核,他們成功消除了傳統推理方式中的性能瓶頸,為實時性要求極高的應用提供了更高效、更可靠的解決方案。
未來,隨著LLM模型的不斷發展和應用領域的不斷拓展,Megakernel優化方法有望在更多領域發揮重要作用,推動AI技術的進一步發展。