在AI領(lǐng)域,一款名為DeepSeek R1的大模型在問世僅128天后,便迅速在業(yè)界掀起了波瀾。這款模型以其獨特的策略,對整個大模型市場產(chǎn)生了深遠的影響。
DeepSeek R1的推出,首先在大模型價格方面帶來了顯著變化。據(jù)悉,OpenAI在六月更新的o3價格相較于之前的o1版本,直接打了兩折。這一變化無疑與DeepSeek R1的競爭力息息相關(guān),它憑借強大的性能和相對較低的價格,成功打破了市場的平衡。
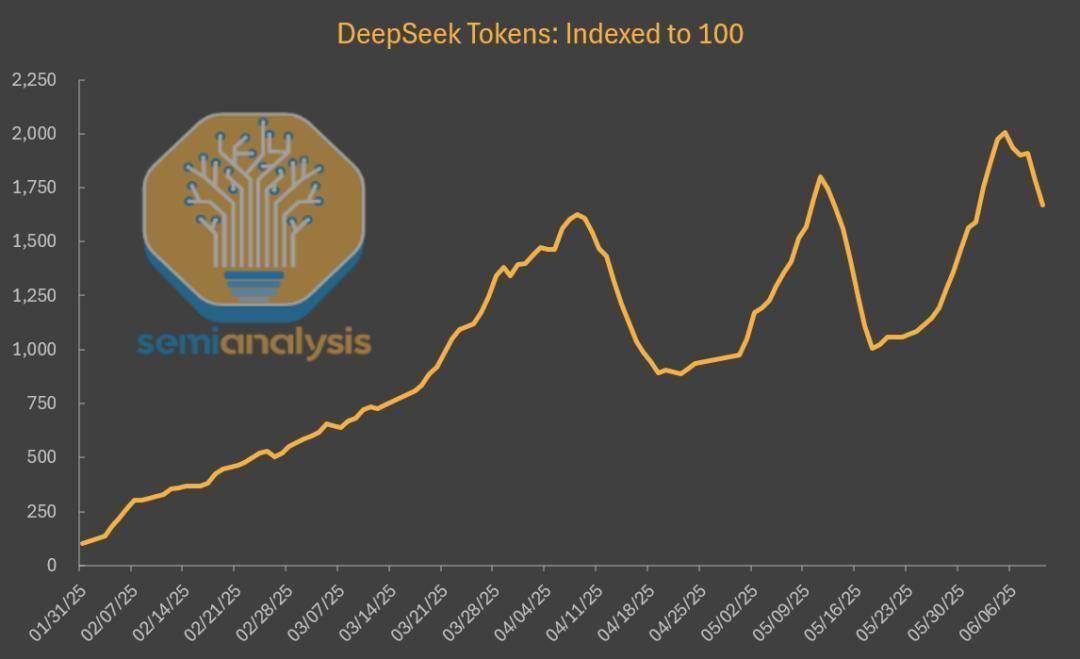
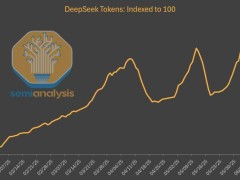
與此同時,DeepSeek模型在第三方平臺上的使用量呈現(xiàn)出爆炸式增長。與剛發(fā)布時相比,使用量增長了近20倍,這一驚人的增長速度不僅推動了DeepSeek自身的普及,也為眾多云計算廠商帶來了可觀的收益。
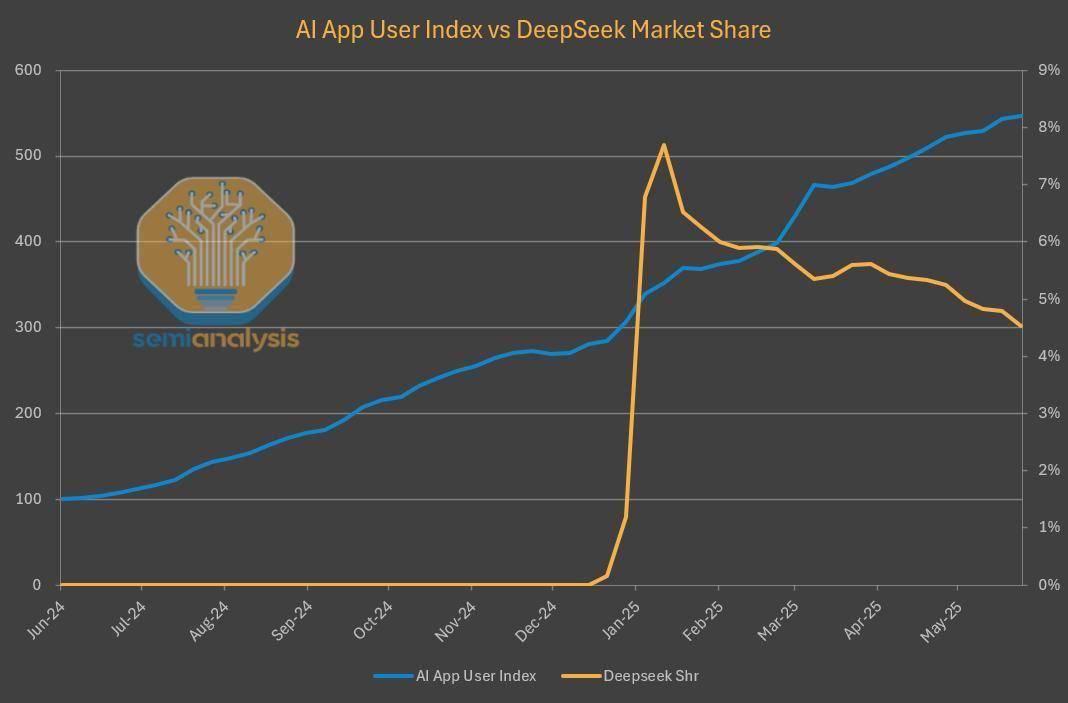
然而,令人意外的是,盡管DeepSeek在第三方平臺上大放異彩,但其自家網(wǎng)站和API的市場份額卻并未隨之提升,反而出現(xiàn)了下滑趨勢。這一變化與AI產(chǎn)品市場整體持續(xù)增長的趨勢形成了鮮明對比,引發(fā)了業(yè)界的廣泛關(guān)注。
據(jù)SemiAnalysis發(fā)布的一份報告指出,DeepSeek之所以能夠在價格上占據(jù)優(yōu)勢,很大程度上得益于其在服務(wù)質(zhì)量上所做的妥協(xié)。用戶在DeepSeek官方平臺上使用模型時,往往需要等待數(shù)秒才能看到第一個字符的出現(xiàn),這一延遲現(xiàn)象相較于其他平臺顯得尤為明顯。盡管DeepSeek V3與R1模型在版本更新后性能有所提升,但延遲問題并未得到有效解決。
報告還指出,DeepSeek在推理計算資源上進行了精心調(diào)配,將有限的資源更多地用于內(nèi)部研發(fā),而非外部推理服務(wù)。這一策略導(dǎo)致DeepSeek在官方平臺上提供的上下文窗口大小相較于其他主流模型提供商顯得較小,無法滿足一些特定場景下的需求。因此,許多用戶轉(zhuǎn)而選擇第三方平臺,以獲取更大的上下文窗口和更快的響應(yīng)速度。
盡管DeepSeek在官方平臺上的表現(xiàn)不盡如人意,但其開源策略卻為其贏得了廣泛的影響力和生態(tài)培養(yǎng)機會。許多云服務(wù)提供商紛紛托管DeepSeek模型,進一步推動了其普及和應(yīng)用。
在DeepSeek的影響下,其他大模型供應(yīng)商也開始調(diào)整策略。例如,Claude為了緩解算力緊張的問題,降低了輸出速度,但仍努力平衡用戶體驗。Claude模型還被設(shè)計成生成更簡潔的回復(fù),以在同等條件下減少token的使用量。
隨著AI競賽的日益激烈,大模型供應(yīng)商們正在不斷探索新的優(yōu)化策略。他們不再僅僅追求模型的智能上限,而是更加注重提升每個token所能提供的智能。這一趨勢無疑將推動AI技術(shù)的進一步發(fā)展,為用戶帶來更加高效、智能的體驗。