近日,一款名為Kimi-Dev-72B的全新開源代碼大模型震撼發布,由神秘團隊月之暗面在凌晨悄然推出,專為軟件工程任務設計。
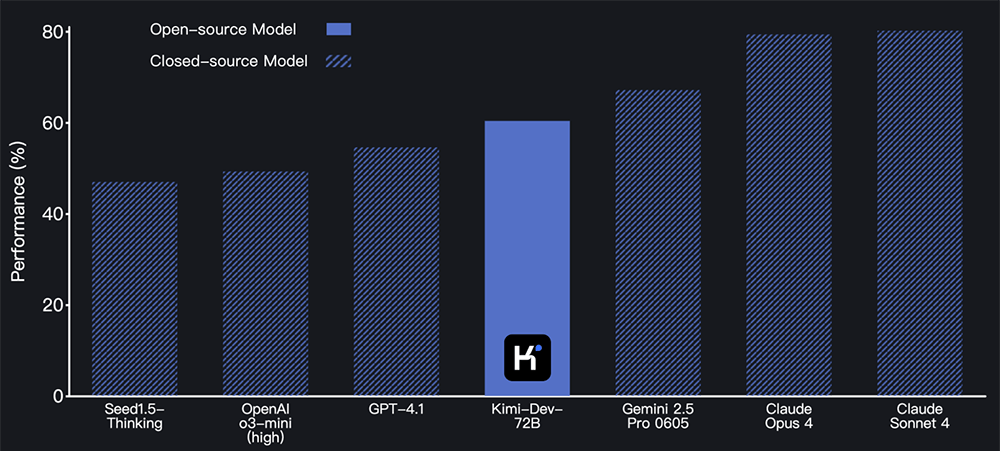
這款模型在業界權威的SWE-bench Verified編程基準測試中大放異彩,以僅720億參數的規模,力壓群雄,成績超越了不久前發布的、參數高達6710億的新版DeepSeek-R1,樹立了開源模型的新標桿。

在SWE-bench Verified測試中,Kimi-Dev-72B取得了高達60.4%的驚人分數,這一成績不僅彰顯了其卓越的軟件工程能力,也標志著開源模型在AI輔助編程領域邁出了重要一步。
Kimi-Dev-72B的成功并非偶然。其背后是月之暗面團隊通過大規模強化學習進行的精心優化。該模型能夠自主修補Docker中的真實存儲庫,并且只有當整個測試套件通過時才會獲得獎勵,從而確保了解決方案的正確性和穩健性,符合現實世界的開發標準。
目前,Kimi-Dev-72B已在Hugging Face和GitHub上開放下載和部署。用戶不僅可以獲取模型權重和源代碼,技術報告也將隨后推出,為社區提供了寶貴的研究資源。
Kimi-Dev-72B的設計理念和技術細節同樣令人矚目。月之暗面團隊巧妙地將BugFixer和TestWriter相結合,形成了獨特的雙重設計。這一設計使得模型在修復代碼錯誤和編寫單元測試方面都能表現出色。同時,通過中期訓練和強化學習,Kimi-Dev-72B進一步增強了其編程能力。
在中期訓練階段,月之暗面團隊使用了約1500億個高質量的真實數據,以Qwen 2.5-72B基礎模型為起點,精心構建了數據配方,使Kimi-Dev-72B能夠學習人類開發者如何推理GitHub問題、編寫代碼修復和單元測試。這一階段的訓練為后續的強化學習打下了堅實的基礎。
而在強化學習階段,Kimi-Dev-72B則專注于提升其代碼編輯能力。月之暗面團隊采用了高效的策略優化方法,并重點關注了僅基于結果的獎勵、高效的提示集以及正例強化等關鍵設計。這些設計使得模型在訓練過程中能夠更有效地利用資源,提升性能。
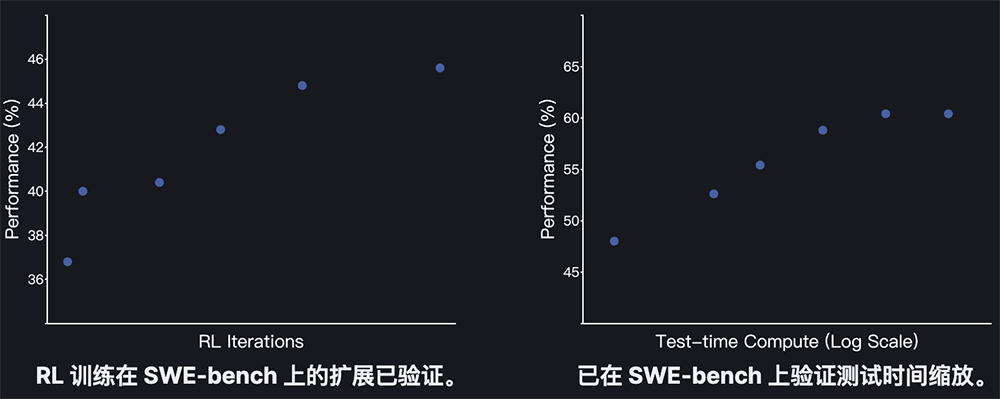
Kimi-Dev-72B在測試過程中還采用了自我博弈機制。這一機制使得模型能夠協調自身Bug修復和測試編寫的能力,進一步提升了其整體性能。