隨著人工智能領域對算力的需求呈現指數級增長,大智算集群已成為模型訓練不可或缺的基礎設施。這一趨勢的背后,是模型參數與數據量的不斷膨脹,驅動著算力需求的急劇上升。從GPT、Llama到Grok等主流模型的發展歷程中,算力需求的增長尤為顯著,Grok-4等最新模型的算力需求已較早期模型提升了近千倍。
在大規模集群訓練的場景下,算力需求的增長帶來了前所未有的挑戰。以DeepSeek、Kimi K2及GPT-4等模型為例,其訓練所需的算力及時間成本均極為高昂。即便是采用高性能的英偉達H100集群,訓練這些模型也需耗費數十天乃至數百天的時間。因此,單純依靠擴大集群規模已難以滿足當前的算力需求,亟需探索新的解決方案。
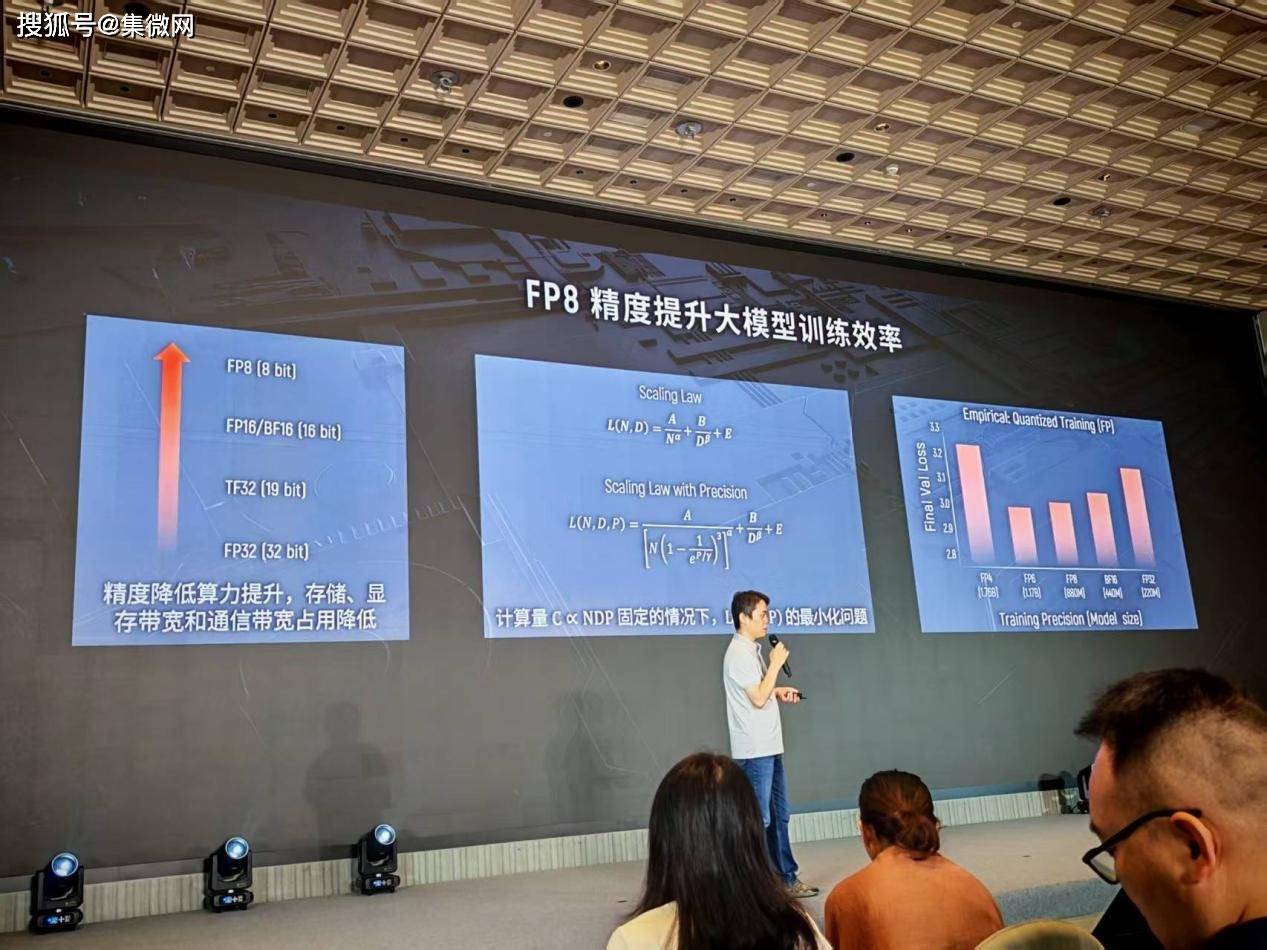
在這一背景下,低精度訓練成為了提升訓練效率的關鍵途徑。從FP32到FP16,再到如今的FP8,精度的降低帶來了算力的顯著提升。然而,精度的下降也伴隨著模型效果的損失。如何在精度與算力之間找到平衡點,成為了業界關注的焦點。摩爾線程副總裁王華在WAIC2025期間的摩爾線程技術分享日上,以《基于FP8的國產萬卡訓練》為主題,分享了摩爾線程在這一領域的創新與思考。
王華指出,通過引入精度參數,可以構建新的Scaling Law模型,從而在參數量、數據量與精度之間找到最優配置。實驗結果表明,FP8成為了精度與算力之間的最佳平衡點。然而,低精度訓練也面臨著諸多挑戰,如數值范圍小、易上溢下溢等問題。為解決這些問題,摩爾線程采用了混合精度訓練等技術手段,對非敏感部分采用FP8進行計算,而對敏感部分則繼續使用高精度。
在軟硬件支持方面,摩爾線程提供了全棧的完整解決方案。硬件上,其GPU支持從FP64到FP8的全精度算力;軟件上,摩爾線程推出了Torch-MUSA、MT-MegatronLM及MT-TransformerEngine等開源框架,這些框架均支持FP8混合精度訓練,并實現了對FP8數據類型的完整支持。在此基礎上,摩爾線程成功復現了DeepSeek-V3的整個訓練過程,成為業內率先能復現DeepSeek滿血版訓練的廠商。
王華還分享了摩爾線程在FP8訓練上的探索與實驗。在scaling factor的選擇及outlier的影響等方面,摩爾線程進行了深入的研究,并提出了有效的解決方案。例如,在scaling factor的選擇上,摩爾線程采用了Per-Tensor及JIT動態的scaling factor選擇策略;在降低outlier影響方面,則采用了Smooth SwiGLU等技術手段。
在大規模集群訓練方面,摩爾線程同樣取得了顯著的進展。為提高集群訓練的可靠性,摩爾線程引入了起飛檢查、飛行檢查及落地檢查等訓練生命周期管理措施。同時,針對慢節點及容錯訓練等問題,摩爾線程也提出了相應的解決方案。例如,在慢節點檢測方面,摩爾線程通過起飛檢查階段的小工作負載測試及訓練過程中的通信執行時間監測等手段,有效識別并解決了慢節點問題;在容錯訓練方面,則采用了動態摘除故障節點等策略,確保了集群訓練的持續穩定運行。

王華的分享不僅展示了摩爾線程在FP8低精度訓練及大規模集群訓練方面的創新成果,也為業界提供了寶貴的參考與借鑒。隨著人工智能技術的不斷發展,摩爾線程將繼續深耕這一領域,為人工智能的未來發展貢獻更多力量。