英偉達近日在文檔理解領域邁出了重要一步,推出了Llama Nemotron Nano VL視覺-語言模型,這一創新旨在高效且精準地應對復雜的文檔級理解挑戰。
Llama Nemotron Nano VL模型基于先進的Llama 3.1架構,巧妙融合了CRadioV2-H視覺編碼器和Llama 3.1 8B指令微調語言模型。這一結合使得模型能夠同時解析多頁文檔中的視覺和文本元素,支持處理長達16K的上下文,無論是圖像還是文本序列,都能游刃有余。
為了實現視覺與文本的精準對齊,該模型采用了投影層和旋轉位置編碼技術,這一創新極大地優化了token效率,尤其適用于長篇多模態任務。無論是面對多圖像輸入還是復雜的文本解析,Llama Nemotron Nano VL都能展現出卓越的性能。
在模型訓練過程中,英偉達采取了分階段策略。首先,利用豐富的商業圖像和視頻數據集進行交錯式圖文預訓練,為模型打下堅實基礎。隨后,通過多模態指令微調,進一步提升模型的交互式提示能力。最后,重新混合純文本指令數據,以優化模型在標準語言模型基準上的表現。
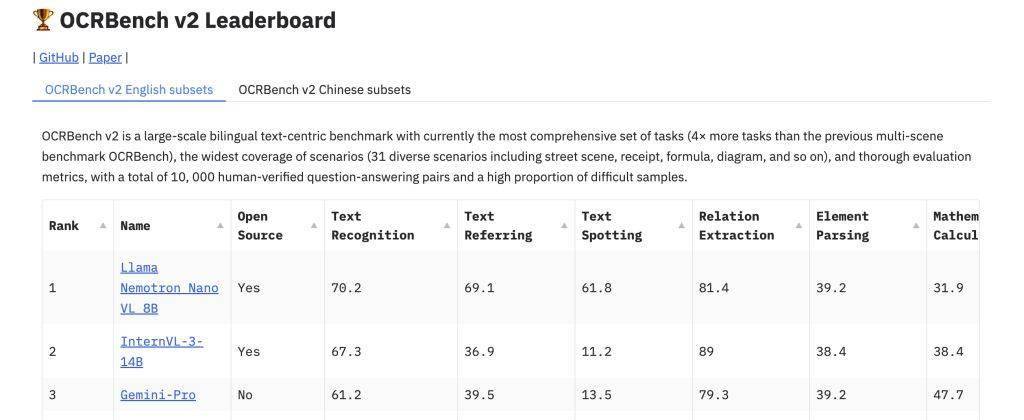
訓練過程中,英偉達采用了自家的Megatron-LLM框架和Energon數據加載器,依托強大的A100和H100 GPU集群完成。在OCRBench v2基準測試中,Llama Nemotron Nano VL在OCR、表格解析和圖表推理等任務上展現了領先精度,尤其在結構化數據提取(如表格和鍵值對)及布局相關問題解答中,表現尤為突出,甚至媲美更大規模的模型。
在部署方面,Llama Nemotron Nano VL同樣表現出色。其設計靈活,支持服務器和邊緣推理場景,滿足多樣化的應用需求。英偉達還提供了4-bit量化版本(AWQ),結合TinyChat和TensorRT-LLM實現高效推理,兼容Jetson Orin等受限環境。該模型還支持Modular NIM(NVIDIA推理微服務)、ONNX和TensorRT導出,為企業應用提供了豐富的解決方案。
為了進一步降低靜態圖像文檔處理的延遲,英偉達還引入了預計算視覺嵌入選項。這一創新使得Llama Nemotron Nano VL在處理圖像文檔時更加高效,為企業用戶帶來了實質性的便利。