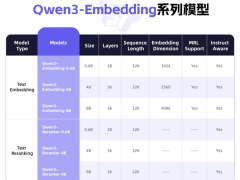
近日,北京智源人工智能研究院震撼發布“悟界”系列大模型,標志著人工智能領域邁入了一個嶄新的階段。這一系列包含了多項全球首創的技術突破,其中尤為引人注目的是“悟界·Emu3”,作為全球首個原生多模態世界模型,它展現了前所未有的能力。
與此同時,研究院還推出了“悟界·見微 Brainμ”,這是全球首個基于腦科學的多模態通用基礎模型。這兩項技術的發布,不僅拓寬了人工智能的應用邊界,更為腦科學與人工智能的融合探索提供了新的可能。
“悟界”系列大模型還涵蓋了悟界·具身智能大模型的多個組成部分。其中,悟界·RoboOS 2.0作為全球首個支持MCP的跨本體大小腦協作框架,為機器人的智能化發展開辟了新路徑。悟界·RoboBrain 2.0作為具身大腦大模型,以及全原子微觀生命模型悟界·OpenComplex2的發布,進一步豐富了具身智能領域的研究成果。
回顧去年10月,智源研究院首次亮相的原生多模態世界模型Emu3,便以其獨特的技術優勢引起了廣泛關注。該模型無需依賴復雜的擴散模型或組合方法,僅憑對下一個token的預測,便能實現對文本、圖像、視頻三種模態數據的全面理解和生成。Emu3的多模態輸入與輸出能力,驗證了自回歸框架在多模態領域的廣泛適用性和先進性,為跨模態交互技術的發展奠定了堅實基礎。
在Emu3的基礎上,見微 Brainμ進一步拓展了多模態技術的應用范圍。它基于Emu3的底層架構,將神經科學與腦醫學相關的fMRI、EEG、雙光子等腦信號進行統一token化處理。借助預訓練模型的多模態對齊優勢,見微 Brainμ能夠實現多模態腦信號與文本、圖像等模態之間的多向映射,從而完成跨任務、跨模態、跨個體的統一通用建模。這一技術突破,使得單一模型即可應對多種神經科學的下游任務,極大地提高了研究效率和準確性。

Emu3所生成的圖像,不僅展示了其強大的生成能力,也預示著人工智能在藝術創作領域的無限潛力。隨著“悟界”系列大模型的持續研發和應用,我們有理由相信,人工智能將在更多領域展現出其獨特的價值和魅力。