蘋果公司在強化學習領域邁出了創新步伐,其研究人員最近提出了一種名為“基于清單反饋的強化學習”(RLCF)的新方法。這一方法旨在優化大語言模型(LLMs)處理復雜指令的能力,摒棄了傳統的人類點贊或點踩評分模式。
RLCF,全稱Reinforcement Learning from Checklist Feedback,它的核心在于為每個用戶指令生成詳細的檢查清單,并根據0到100分的評分系統對每一項進行評判。這一改變,使得模型在優化過程中能夠接收到更加具體和針對性的反饋,而非僅僅依賴于籠統的人類喜好。
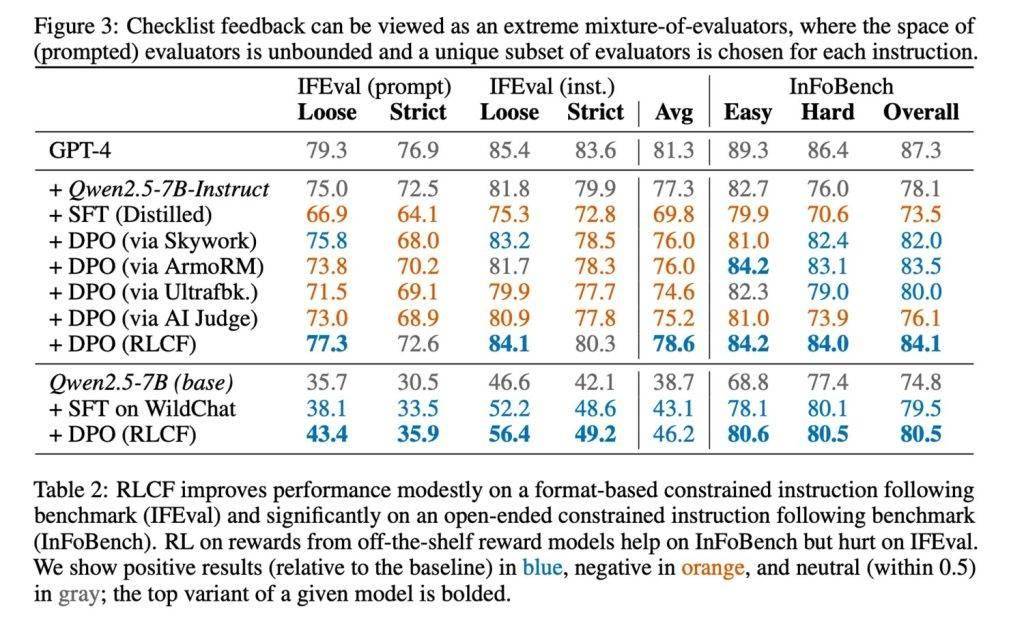
為了驗證RLCF方法的有效性,研究團隊在強指令跟隨模型Qwen2.5-7B-Instruct上進行了測試,測試涵蓋了五個常用的評測基準。結果顯示,RLCF在所有測試中均取得了顯著提升:FollowBench的硬性滿意率提高了4個百分點,InFoBench提升了6點,Arena-Hard的勝率增加了3點,部分任務的最大提升甚至達到了8.2%。這些數據無疑證明了清單反饋在應對復雜、多步驟任務時的強大效果。
在清單的生成方面,蘋果的研究團隊也展現出了獨到的見解。他們利用規模更大的Qwen2.5-72B-Instruct模型,結合現有的研究方法,為13萬條指令創建了名為“WildChecklists”的數據集。這些數據集中的清單條目都是明確的二元判斷項,例如“是否準確翻譯為目標語言”。隨后,大模型會對候選回答進行逐項評分,并將這些評分綜合加權,作為小模型訓練的獎勵信號。
然而,蘋果研究者也坦誠地指出了RLCF方法的局限性。首先,它依賴于性能更強的模型作為評判者,這在資源受限的環境下可能難以實現。其次,RLCF專注于提升復雜指令的執行能力,并未專門設計用于安全性對齊,因此不能替代安全性評估與優化。對于其他類型的任務,該方法的適用性仍需進一步的研究和驗證。