近日,備受矚目的SuperCLUE發(fā)布了其最新的《中文大模型基準(zhǔn)測(cè)評(píng)報(bào)告》,該報(bào)告詳細(xì)闡述了2025年5月份中文大模型的最新表現(xiàn)。
在此次測(cè)評(píng)中,豆包1.5·深度思考模型(Doubao-1.5-thinking-pro)與商湯日日新V6多模態(tài)模型(SenseNova-V6 Reasoner)脫穎而出,成功奪得金牌,將Gemini 2.5 Flash Preview甩在身后,領(lǐng)跑國(guó)內(nèi)大模型的第一梯隊(duì)。
緊隨其后的是第二梯隊(duì)的大模型們,包括DeepSeek-R1、NebulaCoder-V6、Hunyuan-T1和DeepSeek-V3,它們雖然在本次測(cè)評(píng)中未能摘得金牌,但同樣展現(xiàn)出了不俗的實(shí)力。
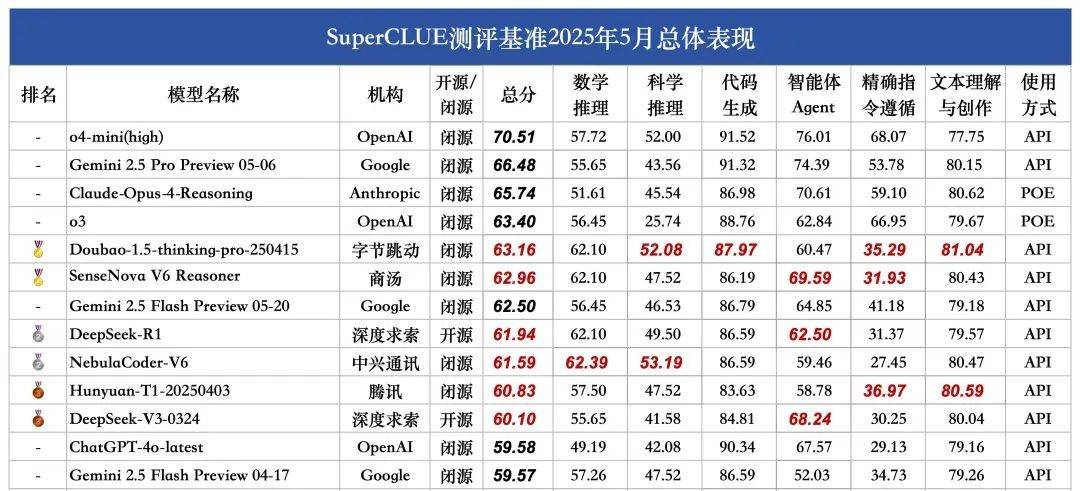
據(jù)報(bào)告分析,國(guó)內(nèi)外第一梯隊(duì)大模型在中文領(lǐng)域的通用能力差距正在逐漸縮小,這對(duì)于國(guó)產(chǎn)大模型來(lái)說(shuō)無(wú)疑是一個(gè)好消息。其中,Doubao-1.5-thinking-pro-205415和SenseNova V6 Reasoner的表現(xiàn)尤為搶眼,它們?cè)诙鄠€(gè)測(cè)評(píng)任務(wù)中都展現(xiàn)出了卓越的能力。
本次SuperCLUE的測(cè)評(píng)報(bào)告聚焦大模型的通用能力,涵蓋了數(shù)學(xué)推理、科學(xué)推理、代碼生成、智能體Agent、精確指令遵循以及文本理解與創(chuàng)作六大任務(wù),總計(jì)1579道多輪簡(jiǎn)答題。這些任務(wù)全面考察了大模型在不同場(chǎng)景下的應(yīng)用能力和表現(xiàn)。
SuperCLUE作為行業(yè)權(quán)威的通用大模型綜合性測(cè)評(píng)基準(zhǔn),其發(fā)布的報(bào)告一直備受關(guān)注。此次報(bào)告的發(fā)布,不僅揭示了當(dāng)前中文大模型的最新發(fā)展態(tài)勢(shì),也為未來(lái)大模型的研究和應(yīng)用提供了重要的參考依據(jù)。