阿里通義千問Qwen團(tuán)隊(duì)近日正式推出了其最新研發(fā)成果——QwenLong-L1-32B模型,這一模型在長文本情境推理領(lǐng)域?qū)崿F(xiàn)了新的突破。據(jù)團(tuán)隊(duì)介紹,QwenLong-L1-32B是首個(gè)通過強(qiáng)化學(xué)習(xí)訓(xùn)練的長文本情境推理模型(LRM),其性能在多個(gè)基準(zhǔn)測試中表現(xiàn)優(yōu)異。
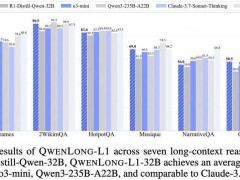
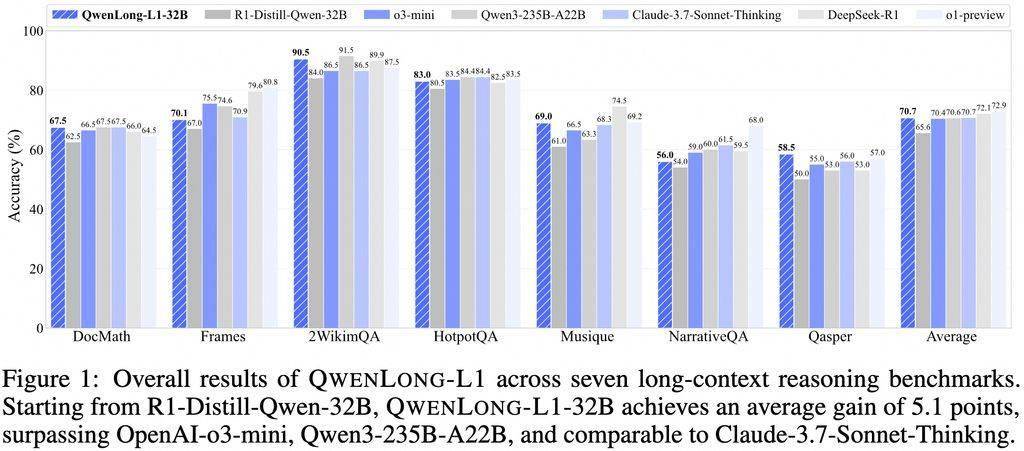
在七個(gè)長文本DocQA基準(zhǔn)測試中,QwenLong-L1-32B模型的表現(xiàn)超越了o3-mini和Qwen3-235B-A22B等旗艦?zāi)P停cClaude-3.7-Sonnet-Thinking模型旗鼓相當(dāng)。這一成績不僅展示了QwenLong-L1-32B模型的強(qiáng)大實(shí)力,也標(biāo)志著阿里在長文本推理技術(shù)上的又一次飛躍。
QwenLong-L1-32B模型的最大亮點(diǎn)在于其上下文窗口的支持能力,最高可達(dá)131072個(gè)tokens。這意味著模型在處理長文本時(shí)能夠捕捉到更多的上下文信息,從而做出更準(zhǔn)確的推理。這一特性使得QwenLong-L1-32B模型在長文本推理任務(wù)中具有顯著的優(yōu)勢。
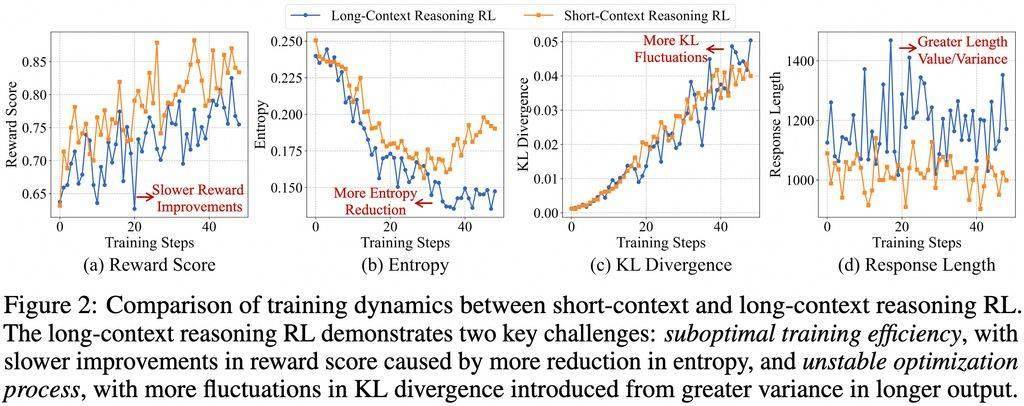
在模型的開發(fā)過程中,阿里通義千問Qwen團(tuán)隊(duì)采用了先進(jìn)的GRPO(Group Relative Policy Optimization)和DAPO(Direct Alignment Policy Optimization)算法,并結(jié)合了基于規(guī)則和基于模型的混合獎(jiǎng)勵(lì)函數(shù)。這些創(chuàng)新技術(shù)的應(yīng)用,顯著提升了模型在長上下文推理中的準(zhǔn)確性和效率。團(tuán)隊(duì)還通過監(jiān)督微調(diào)(SFT)階段建立了一個(gè)穩(wěn)健的初始策略,并采用課程引導(dǎo)的分階段強(qiáng)化學(xué)習(xí)技術(shù)來穩(wěn)定策略演變。
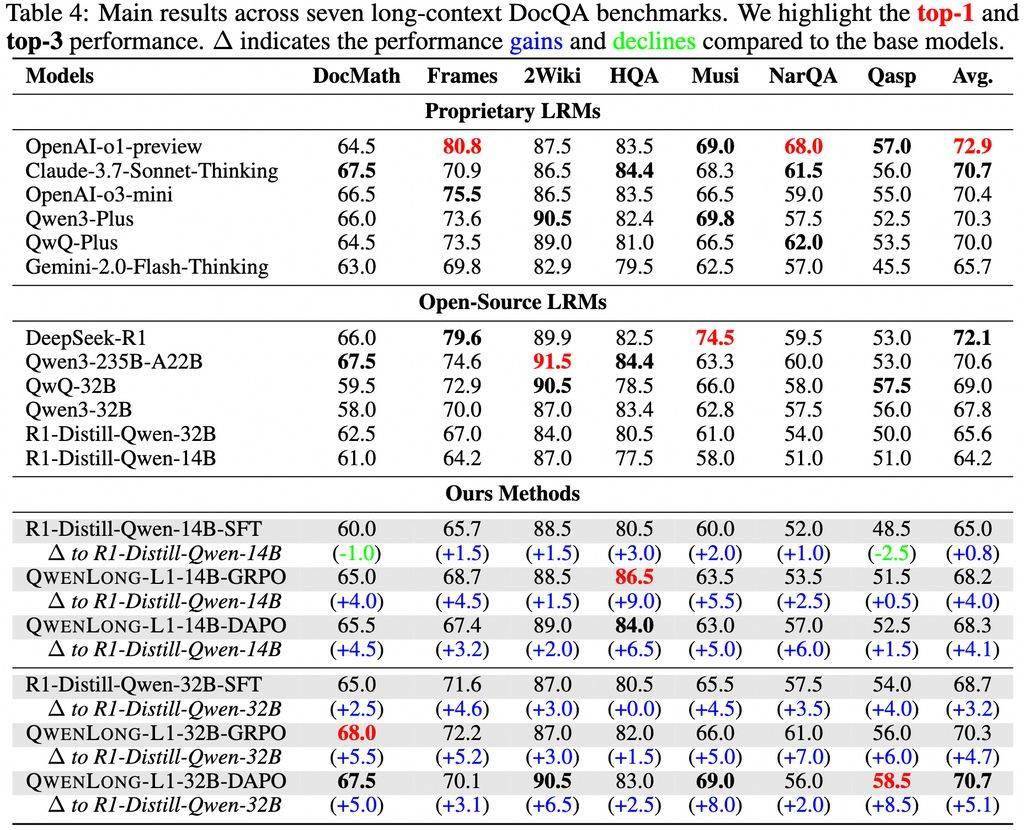
除了模型本身的創(chuàng)新,阿里還發(fā)布了一套針對長文本推理問題的完整解決方案。該方案涵蓋了高性能的QwenLong-L1-32B模型、專門優(yōu)化的訓(xùn)練數(shù)據(jù)集、創(chuàng)新的強(qiáng)化學(xué)習(xí)訓(xùn)練方法以及全面的性能評(píng)估體系。這一解決方案的推出,將為長文本推理領(lǐng)域的研究和應(yīng)用提供有力的支持。
阿里通義千問Qwen團(tuán)隊(duì)的這一成果,不僅展示了其在長文本推理技術(shù)上的深厚積累和創(chuàng)新實(shí)力,也為人工智能領(lǐng)域的發(fā)展注入了新的活力。隨著技術(shù)的不斷進(jìn)步和應(yīng)用場景的不斷拓展,相信QwenLong-L1-32B模型將在更多領(lǐng)域發(fā)揮重要作用。