阿里巴巴旗下的Qwen團隊近日宣布了一項重大進展,他們最新一代的旗艦編程模型Qwen3-Coder-480B-A35B-Instruct已正式向公眾開源。這款模型被Qwen團隊譽為迄今為止最強大的開源智能體編程模型,不僅在參數規模上達到了480B,而且在智能體編程、瀏覽器使用以及工具調用等多個任務上均展現出卓越的性能。
據Qwen團隊介紹,Qwen3-Coder在基準測試中取得了開源領域的頂尖成績,超越了包括Kimi K2、DeepSeek V3在內的多個開源模型,以及閉源模型GPT-4.1,其表現甚至可與以編程能力見長的Claude Sonnet 4相媲美。這款模型原生支持256K上下文,并可通過特殊技術擴展至100萬上下文,最大輸出達到6.5萬token,為用戶提供了前所未有的編程體驗。
除了強大的模型本身,Qwen團隊還開源了一個基于Gemini Code分叉而來的智能體編程命令行工具——Qwen Code。這款工具經過定制提示和函數調用協議的適配,能夠更充分地釋放Qwen3-Coder在智能體編程任務上的潛力,為用戶提供更加便捷、高效的編程體驗。
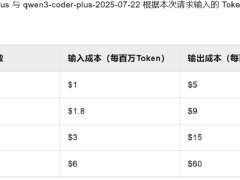
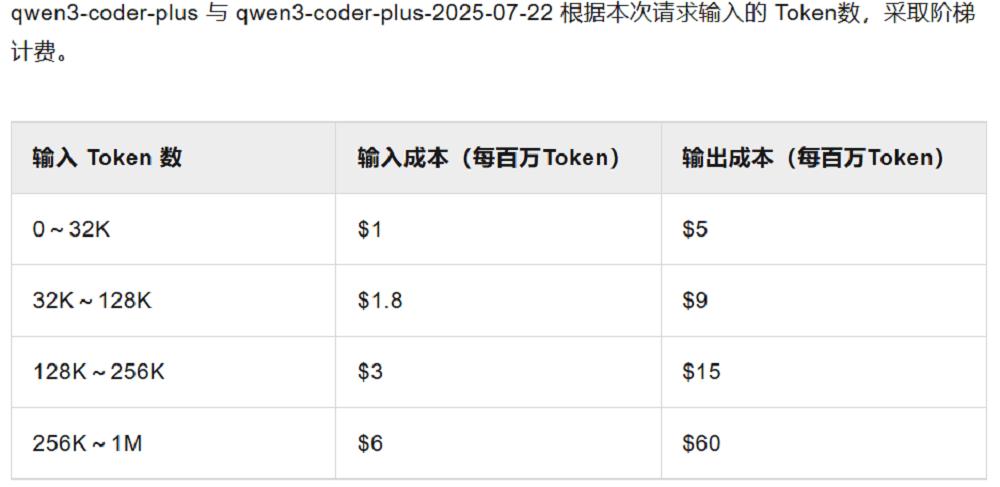
Qwen3-Coder已在阿里云旗下的大模型服務平臺百煉上線,其API采用階梯計費方式,根據輸入token量調整價格。用戶可以根據自身需求選擇合適的計費檔位,靈活控制成本。Qwen3-Coder的480B版本也已在Hugging Face、魔搭等開源社區發布,供用戶下載和本地部署。
在Qwen3-Coder發布前,這一模型已經悄然在Qwen Chat官網上線,引發海外網友的一片熱議。不少網友分享了實測案例,展示了Qwen3-Coder在指令遵循、UI設計、動畫等方面的驚人能力。例如,有網友讓Qwen3-Coder打造一個Wordle單詞游戲,結果模型不僅快速交付了游戲頁面和源代碼,而且在審美和用戶體驗上也達到了較高水準。

在技術層面,Qwen團隊在博客中分享了Qwen3-Coder的部分訓練細節。預訓練階段,模型使用了7.5萬億token數據,其中代碼占比高達70%,確保了模型在編程方面的卓越表現。后訓練階段,Qwen團隊引入了長視距強化學習,鼓勵模型通過多輪交互解決現實世界任務,進一步提升了模型的實用性和泛化能力。
Qwen團隊表示,他們仍在不斷努力提升Coding Agent的性能,旨在讓它承擔更多復雜和乏味的軟件工程任務,從而釋放人類的生產力。未來,Qwen3-Coder的更多模型尺寸也將陸續推出,以滿足不同用戶的需求和場景。