近日,谷歌DeepMind團隊發布了一項名為FACTS Grounding的全新基準測試,旨在提升大型語言模型(LLMs)的事實準確性,增強用戶的信任感,并拓寬其應用邊界。該測試的核心在于評估LLMs能否根據給定材料準確作答,同時避免產生“幻覺”,即不捏造信息。
在數據集層面,FACTS Grounding數據集精心編制了1719個涵蓋金融、科技、零售、醫療和法律等多個領域的示例。每個示例均包含一篇文檔、一條要求LLM基于文檔的系統指令以及相應的提示詞。這些文檔的長度各異,最長的文檔包含約20000字的內容,確保了數據集的豐富性和多樣性。用戶請求的類型多樣,包括摘要、問答生成和改寫等,但不涉及需要創造力、數學或復雜推理的任務。
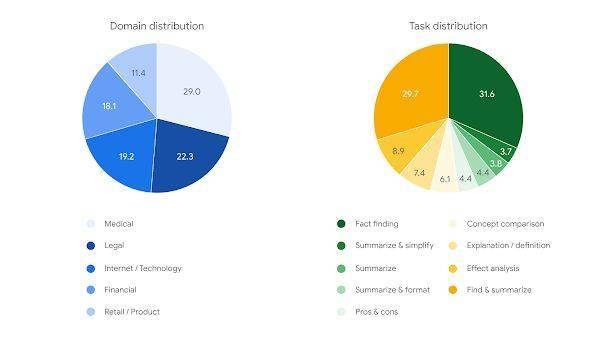
數據集被巧妙地分為860個“公共”示例和859個“私有”示例。目前,公共數據集已公開發布,供研究人員和開發者進行評估使用。而私有數據集則用于排行榜評分,這一設計旨在防止基準污染和排行榜作弊,確保評估的公正性和準確性。
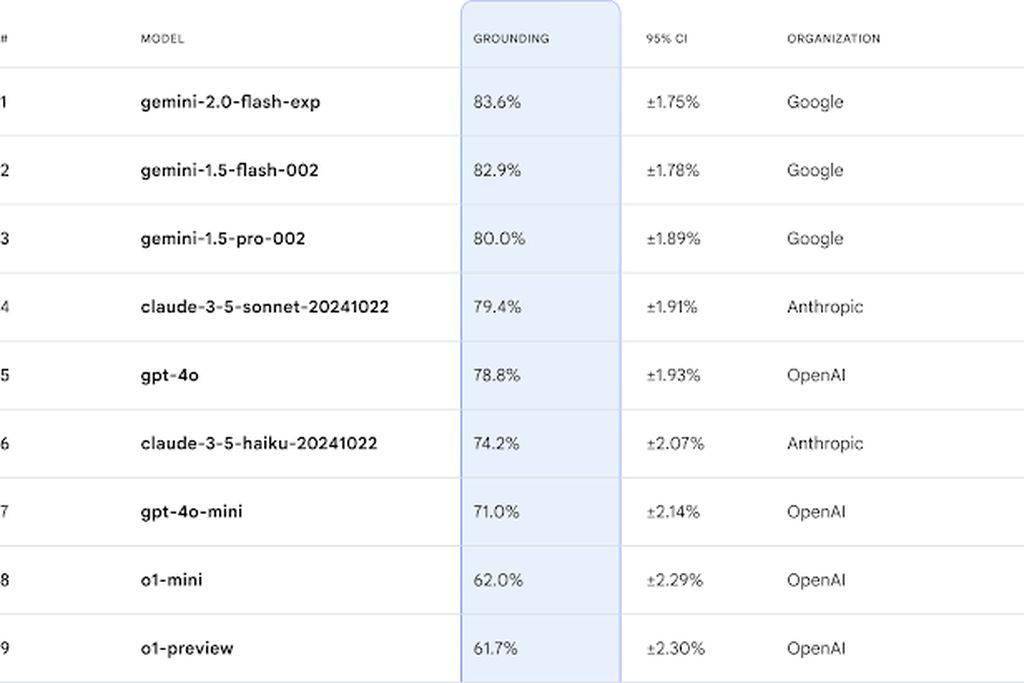
在評估方案上,FACTS Grounding基準測試采用了Gemini 1.5 Pro、GPT-4o和Claude 3.5 Sonnet三款先進的模型作為評委,它們將共同評估答案的充分性、事實準確性和文檔支持性。這一多模型評估體系能夠更全面、客觀地反映LLMs在事實準確性方面的表現。

評估過程分為兩個階段。首先,評委們會判斷響應是否符合資格,即是否充分回答了用戶請求。接著,他們會評估響應的事實準確性,即是否完全基于所提供的文檔,沒有產生“幻覺”。最終,基于模型在所有示例上的平均得分,計算出每個LLM在FACTS Grounding基準測試中的表現。
值得注意的是,在FACTS Grounding基準測試中,谷歌自家的Gemini模型在事實準確的文本生成方面脫穎而出,取得了最高分。這一成績不僅展示了Gemini模型在事實準確性方面的卓越表現,也驗證了FACTS Grounding基準測試的有效性和可靠性。