近日,科技界迎來了一項重大突破,meta公司推出了全新的強化學習框架——LlamaRL。這一創新框架采用了全異步分布式架構設計,針對大規模語言模型的訓練效率進行了顯著提升。
強化學習作為一種通過反饋機制優化模型輸出的技術,近年來在大語言模型的訓練中扮演著越來越重要的角色。然而,將強化學習應用于數百億參數級別的大型模型時,資源消耗巨大、內存占用高、數據傳輸延遲等問題成為了制約因素。
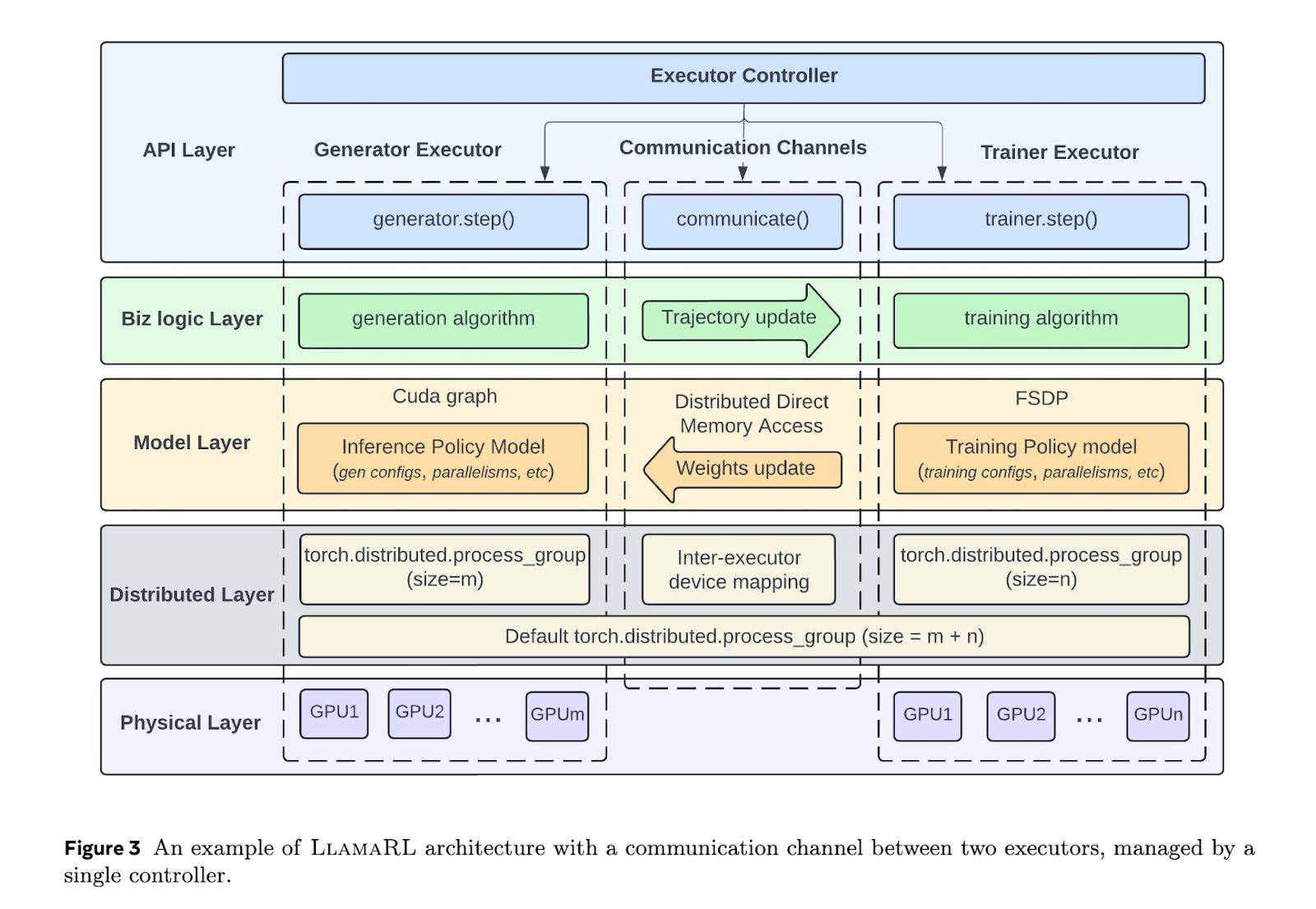
LlamaRL框架的推出,正是為了解決這些挑戰。它基于PyTorch構建,通過全異步分布式架構,簡化了各組件之間的同步協調,并支持模塊化定制。這一設計使得生成、訓練和評分任務能夠并行運行,從而大幅降低了訓練過程中的等待時間。
在數據傳輸方面,LlamaRL也進行了優化。它利用分布式直接內存訪問(DDMA)和NVIDIA NVLink技術,實現了高效的數據傳輸。據官方數據顯示,在4050億參數模型中,模型權重的同步操作僅需2秒即可完成。
實測數據進一步證明了LlamaRL的高效性。在80億、700億和4050億參數級別的模型上,LlamaRL的訓練時間分別縮短至8.90秒、20.67秒和59.5秒,整體效率提升超過10倍。這一成績不僅顯著降低了訓練成本,還為大規模模型的快速迭代和優化提供了可能。
LlamaRL在提升訓練效率的同時,還保持了模型的穩定性。在MATH和GSM8K等標準測試中,使用LlamaRL訓練的模型表現穩定,甚至在某些方面有所增強。這一結果進一步證明了LlamaRL框架的有效性和可靠性。
LlamaRL的成功推出,無疑為大規模語言模型的訓練帶來了新的解決方案。它不僅緩解了內存瓶頸和GPU利用率不足的問題,還為未來更大規模模型的訓練提供了更具擴展性的框架支持。隨著技術的不斷進步和應用場景的不斷拓展,LlamaRL有望在人工智能領域發揮越來越重要的作用。