近日,科技界迎來了一項新的合作成果,蘋果公司與劍橋大學聯手推出了一項創新的AI評估系統。這一系統旨在通過引入外部驗證工具,提升AI評審員的能力,進而增強評估的整體質量。
在評估大型語言模型(LLM)的過程中,研究人員和開發者常常借助AI的力量,也就是所謂的“LLM作為評審員”。然而,這一方法也面臨著不少挑戰,特別是在處理長篇事實核查、高級編碼以及復雜數學問題等任務時,評估的準確性往往會受到影響。
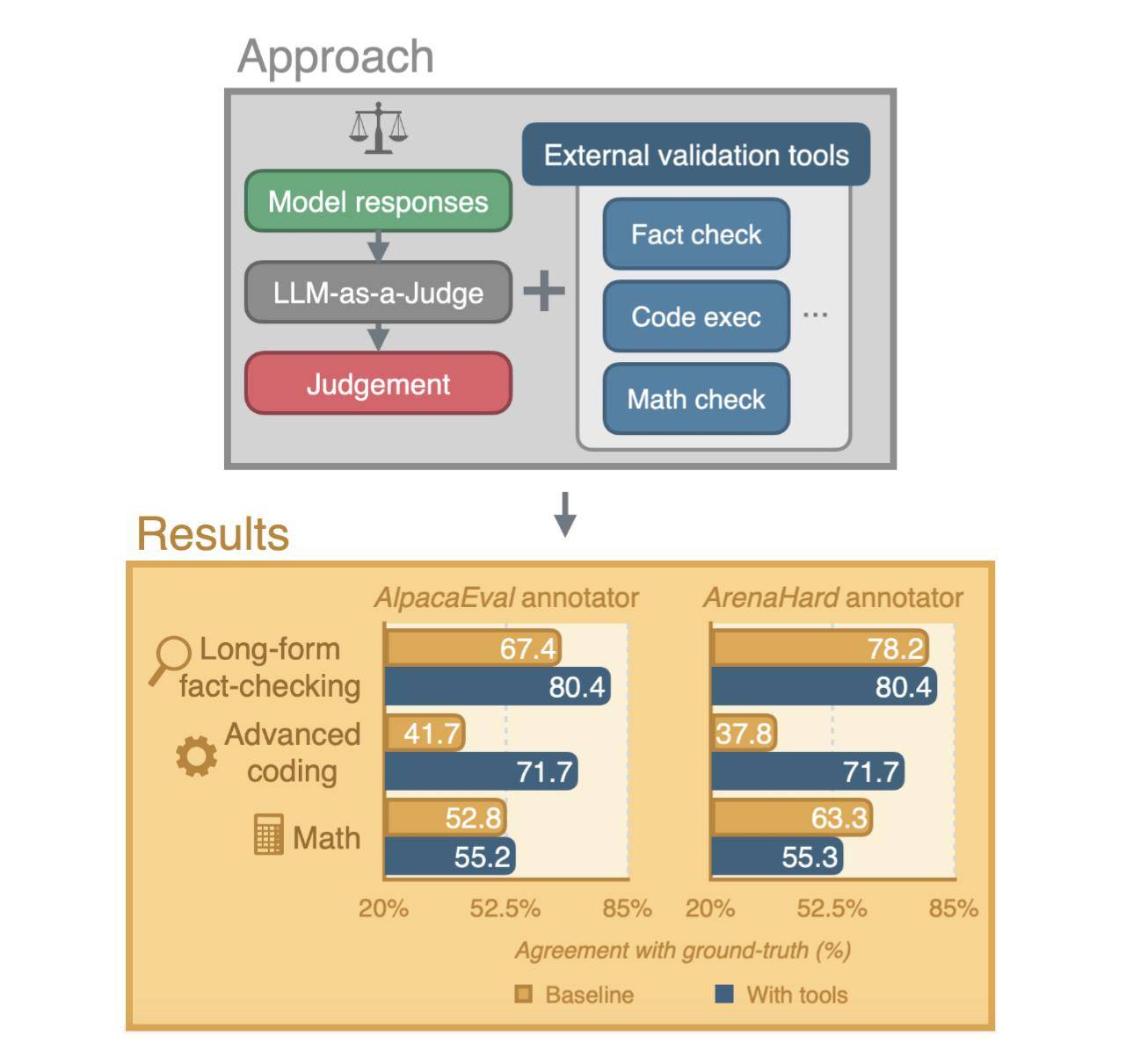
為了克服這些挑戰,蘋果與劍橋大學的研究人員共同發表了一篇新的研究論文,詳細介紹了一種新的評估系統。該系統通過為AI評審員配備外部驗證工具,旨在克服人類和AI在注釋過程中的局限性,從而提高評估的準確性。
人類評審員在評估過程中可能會受到時間限制、疲勞以及個人寫作風格等因素的影響,從而產生偏見。而AI在處理上述復雜任務時,也面臨著不小的困難。為了解決這些問題,研究人員創建了一種具有自主性的評估代理。該代理能夠評估響應,并根據需要選擇使用外部工具,以確保評估的準確性。
評估過程主要包括三個步驟:首先是初始領域評估,其次是工具的使用,最后是最終決策。在工具使用環節,事實核查工具會利用網絡搜索來驗證響應中的事實準確性;代碼執行工具則會借助OpenAI的代碼解釋器來運行并驗證代碼的正確性;而數學核查工具則是代碼執行工具的一個專門版本,用于驗證數學和算術運算的準確性。
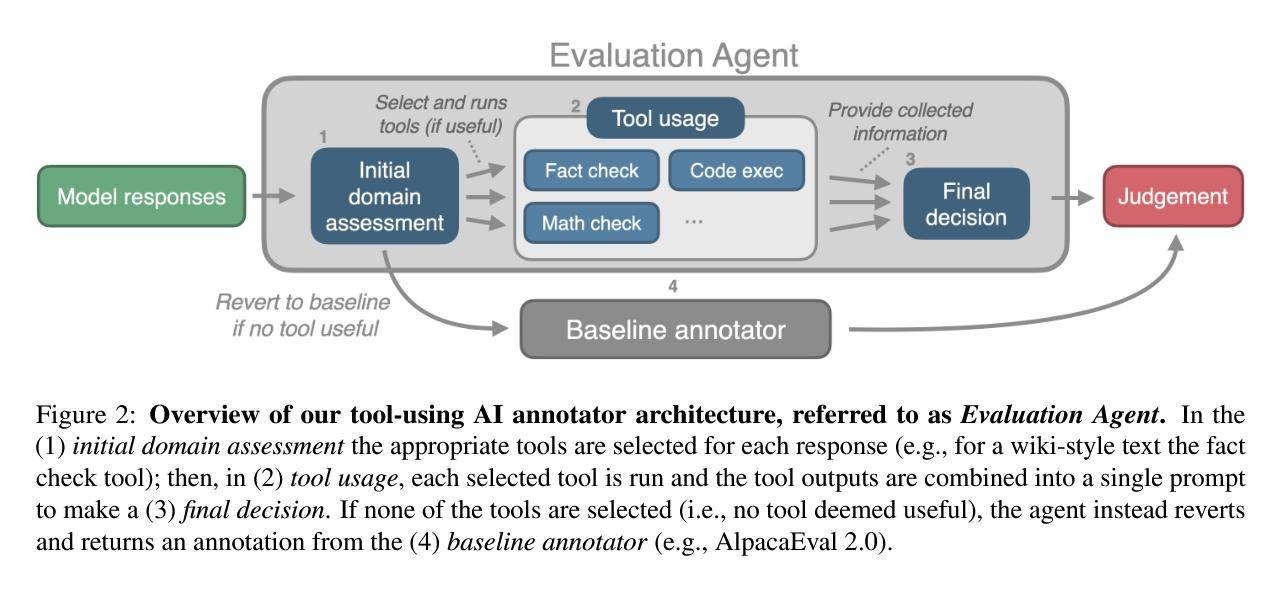
如果評估代理判斷沒有合適的工具可以幫助判斷,那么系統將默認使用基線LLM注釋器,以避免在簡單任務上進行不必要的處理,從而可能導致的性能下降。