近期,上海人工智能實驗室攜手清華大學及美國伊利諾伊大學香檳分校的研究團隊,共同研發出了一種創新方法,用以解決大型語言模型在強化學習過程中的策略熵崩潰問題。這一突破性的進展,得益于Clip-Cov和KL-Cov兩項技術的引入。
隨著大型語言模型(LLMs)在邏輯推理能力上的顯著提升,強化學習(RL)的應用場景得以大幅擴展,從原先的單一任務擴展到更為復雜多變的環境。這一轉變,無疑為模型賦予了更強的泛化能力和邏輯推理能力。然而,強化學習的高計算資源需求以及策略熵下降的問題,成為了制約其進一步發展的關鍵因素。
策略熵,作為衡量模型在利用已知策略和探索新策略之間平衡狀態的指標,其過低會導致模型陷入對已有策略的過度依賴,從而失去對新策略的探索能力。這種探索與利用之間的權衡,正是強化學習的基礎所在。因此,如何有效控制策略熵,成為了強化學習訓練過程中的一大難題。
為解決這一問題,研究團隊提出了一個全新的經驗公式:R = ?a exp H + b,其中R代表下游任務的表現,H為策略熵,a和b為擬合系數。該公式揭示了策略性能與熵值之間的微妙關系,并指出熵耗盡是導致性能瓶頸的主要原因。在此基礎上,團隊進一步分析了熵的動態變化,發現其受到動作概率與logits變化協方差的影響。
針對這一發現,團隊創新性地提出了Clip-Cov和KL-Cov兩項技術。前者通過裁剪高協方差token來維持熵水平,后者則通過施加KL懲罰來達到同樣的效果。實驗結果顯示,這兩項技術在Qwen2.5模型和DAPOMATH數據集上均取得了顯著成效,特別是在AIME24和AIME25等高難度基準測試中,32B模型的性能提升高達15.0%。
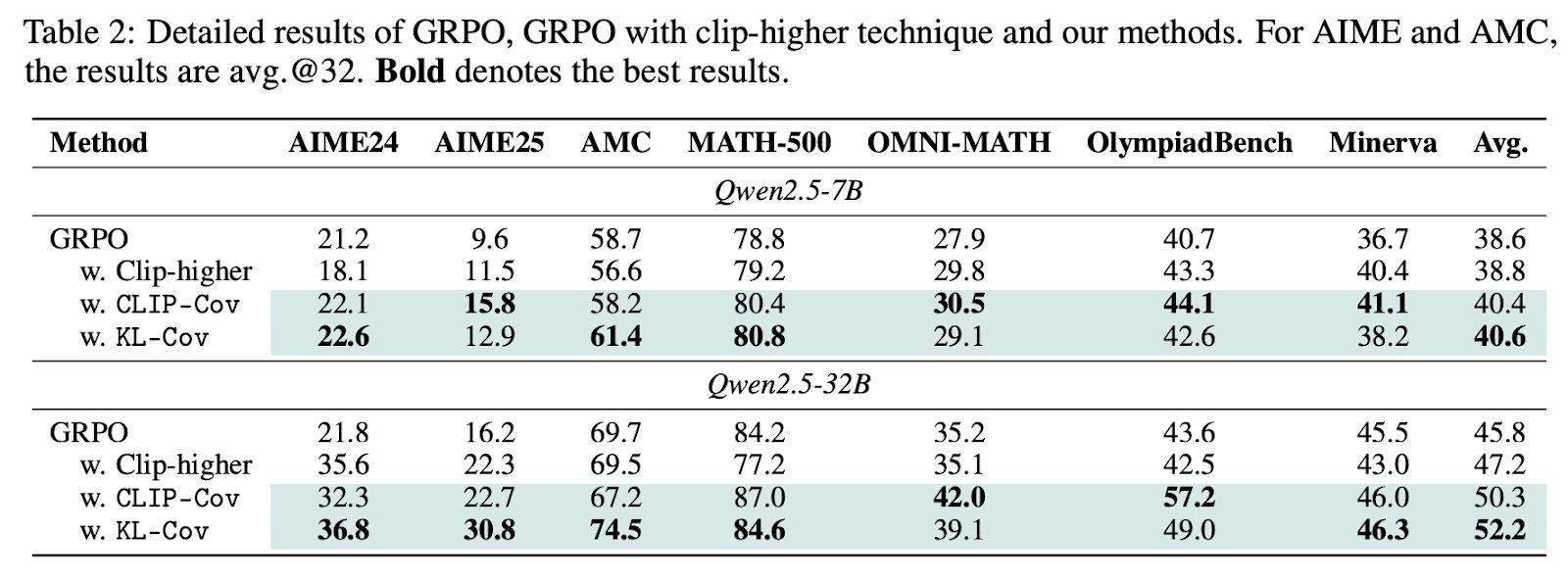
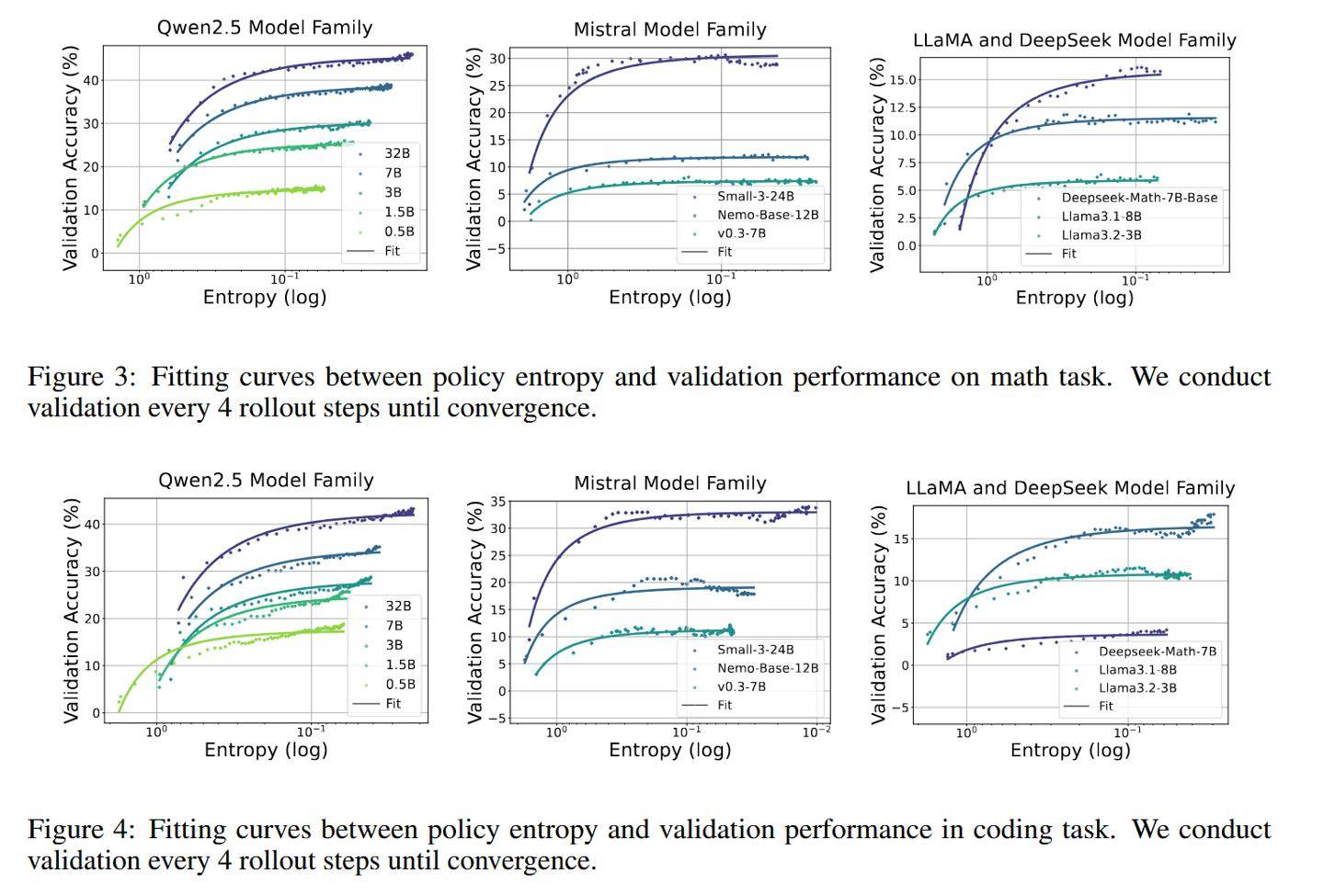
為進一步驗證這兩項技術的有效性,研究團隊還在包括Qwen2.5、Mistral、LLaMA和DeepSeek在內的11個開源模型上進行了測試,這些模型的參數規模從0.5B到32B不等,涵蓋了數學和編程任務的8個公開基準測試。實驗結果表明,Clip-Cov和KL-Cov技術均能在不同模型上維持更高的熵水平,從而顯著提升模型的性能。
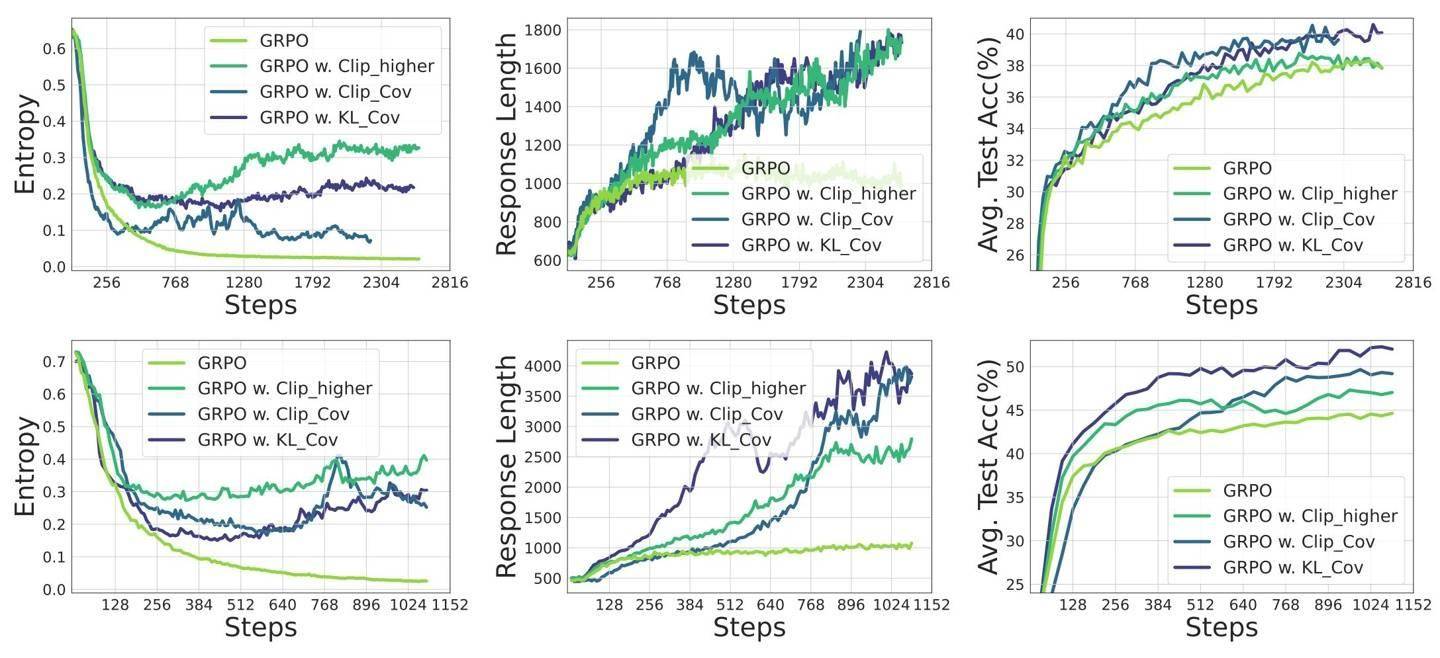
在訓練過程中,研究團隊采用了veRL框架和零樣本設置,并結合了GRPO、REINFORCE++等算法來優化策略性能。實驗結果顯示,KL-Cov方法在基線熵值趨于平穩時,仍能保持10倍以上的熵值,充分證明了其有效性。
此次研究不僅成功解決了策略熵崩潰問題,還為強化學習在語言模型中的擴展提供了堅實的理論支持。研究團隊強調,熵動態是制約性能提升的關鍵瓶頸,未來需要繼續探索更為有效的熵管理策略,以推動語言模型的智能化發展。